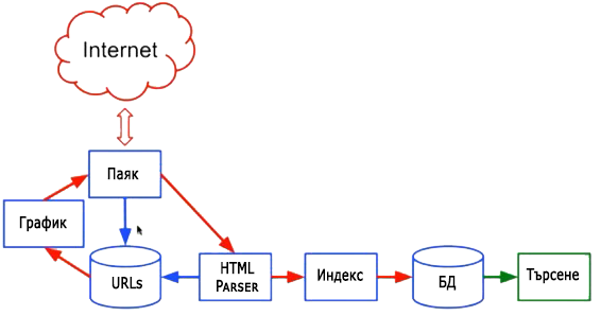
Търсещите машини се намират в центъра на информационните операции в интернет, като всеки ден насочват милиарди интернет потребители към уебсайтове, които се появяват в горната част на страницата с резултатите от търсене. Според повечето автори търсачките са “приложения, които използват ключови думи и фрази за намиране на информация в Интернет[1]“. Тези приложения включват няколко основни компоненти[2]:
- интерфейс за търсене;
- уеб паяци (ботове, роботи);
- бази данни;
- алгоритми за търсене и извличане на информация.

Интерфейсътза търсене е страницата, където се пишат заявките за търсене. Той е връзката между потребителите и базите с данни. В Google интерфейсът е индивидуален, така че потребителите могат да избират няколко опции, като новини, видеоклипове, изображения, публикации и т.н.

Ботовете се дефинират от Google като “общ термин за всяка автоматизирана програма (робот или паяк), използвана за автоматично откриване и сканиране на уебсайтове, като следват връзки от една уеб страница към друга[1].” Уеб ботовете постоянно “обхождат” мрежата за нова информация, като по график проследяват поставените връзки в първоначално създаден списък от сайтове и изтеглят новите страници във формат HTML за последваща обработка и класифициране.

Базите данни съхраняват информацията, извлечена от уеб ботовете (роботите, паяците) и я класифицират в подходящ за възпроизвеждане вид. Всеки път, когато правим заявки в търсачката, ние търсим информация в базите данни[2].

Алгоритмите за търсене и класиране се определят от Google като “компютърни процеси и модели, които правят търсенето значително по-лесно и дават релевантен отговор на запитванията на потребителите[3]“. Всяка търсачка използва различни алгоритми, така че при една и съща заявка за търсене ще се видят различни варианти на резултата.
Ботовете, базите данни, интерфейсът за търсене и алгоритмите са водещи технологии за търсачката, която показва крайния резултат от тяхната работа в интерфейса за търсене.
Работа на Уеб бот
При създаването на една чисто нова уеб страница в Интернет търсещите машини не знаят за нейното съществуване и съответно тя е невидима за хората, които не влизат в нея. Тя не се появява в резултатите от търсене, докато Google не я индексира. Това значи ботовете (обхождащите паяци) на търсачката да я намерят, обработят и да я съхранят в базата данни на Google, където се класифицира и подрежда по тематика и ключови думи.
В своята работа уеб ботовете „обхождат“ мрежата за нова информация движейки се по връзките между страниците. При посещение на индексирана страница те проследяват всички хипервръзки в нея и ако открият нова, неиндексирана страница сканират кода на страницата, заглавията, уеб съдържанието, търсят етикети, описания и инструкции за да научат повече за нейната тема, кой стои зад това, какво прави и какво го интересува, след което записват новите данни с определена точност в базите данни (индексират ги).
Това не е малко работа, като се има в предвид, че всяка минута се изграждат между 300 – 500 нови уебсайта, всеки от които има средно 7 страници. По данни на Internetlivestats.com от септември 2017 г. Google обработва почти 3,8 милиона търсения всяка минута или 5,5 милиарда на денонощие, а в техния индекс се съхранява информация за над 30 трилиона уникални уеб страници и над 100 милиона гигабайта информация[1].
Това е огромно количество информация поради което търсачката много бързо трябва да обработи, класифицира и покаже информацията при търсене за по-малко от секундата.
Когато потребителя направи заявка за определена ключова дума, търсачката намира всички подходящи индексирани уеб страници по тази тематика и ги показва в SERP (страницата с показаните резултати) подредени според ранг по реда на релевантност и авторитет.
Първо са тези с по-голям ранг, после с по-малък ранг и т.н. Този ранг се определя според действащите математически алгоритми, които в днешно време отчитат над 200 информационни параметъра за сайта[2].
[1] Google Search Console. No date. Irrelevant keywords. Accessed on 20 December 2016.
[2] Michigan Public Health Training Center, ei pvm
[3] GoogleInside Search. 2012. Algorithms. Accessed 22 March 2017. https://www.google.com/in-sidesearch/howsearchworks/algorithms.html
[1] Google. No date. Google Crawlers. Accessed 10 January 2017. https://sup-port.google.com/уебmasters/answer/1061943?hl=en
[1] Tilley, S. & Rosenblatt, H. Systems Analysis and Design. Eleventh edition. Boston, MA: Cen-gage Learning